vid2vid提出了一种通用的video to video的生成框架,可以用于很多视频生成任务。常用的pix2pix没有对temporal dynamics建模,所以不能直接用于video synthesis。下面就pose2body对着vid2vide code简单记录一二。
推荐观看vid2vid youtube
1. Network Architecture
1.1 Sequential Generator
sequential generator在生成当前帧时需要考虑:1)当前帧的输入图片;2)前几帧的输入图片;3)前几帧的生成图片。回看多少帧由n_frames_G设置,如下图中n_frames_G设置为3:
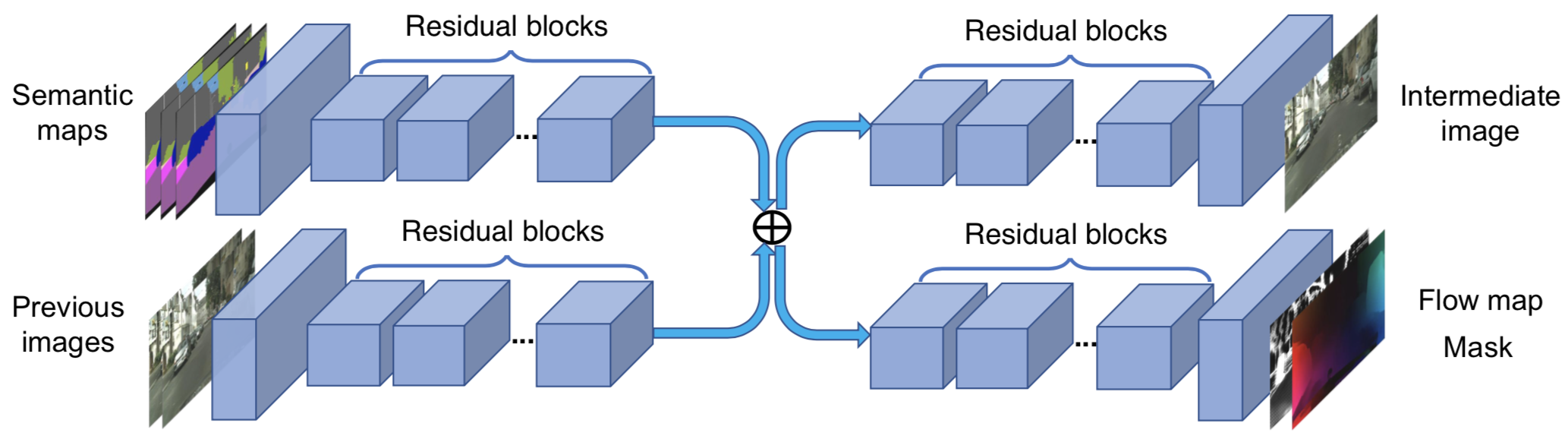
sequential generator可以得到当前帧的预测图intermediate image、前一帧到当前帧的光流图flow map和occlusion mask。之后当前帧的生成结果由前一帧生成结果经由光流warp后的图片(img_warp)和当前帧的预测图(img_raw)通过mask 加权而成,这样做是因为前后连续帧间有非常多的相似信息。
同时对于高分辨率的图片生成,和pix2pixHD一样,提出了coarse-to-fine的generator,通过n_scales_spatial控制:
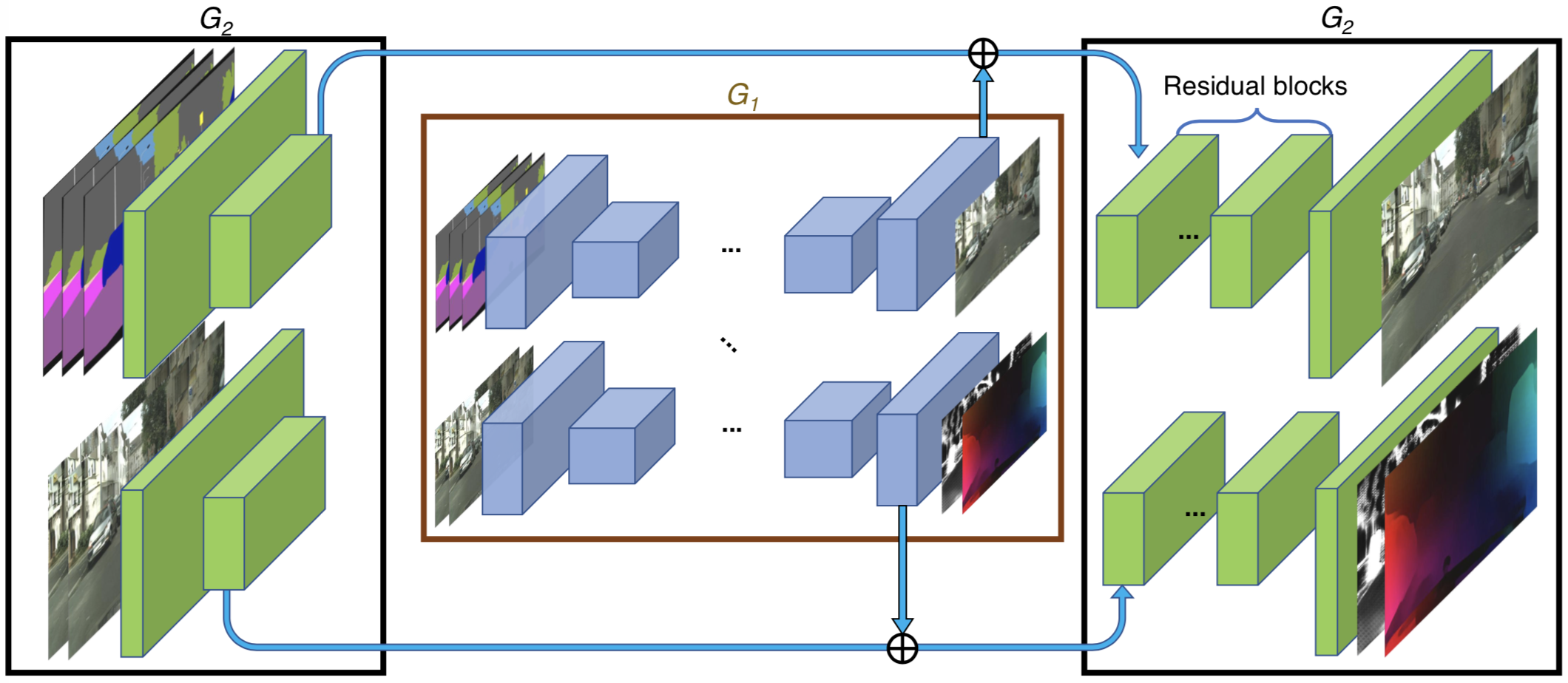
如果是采用coarse-to-fine generator,在训练时可以通过设置niter_fix_global让Local 部分(高分辨率部分)单独先训几个epoch,和pix2pixHD中做法类似。
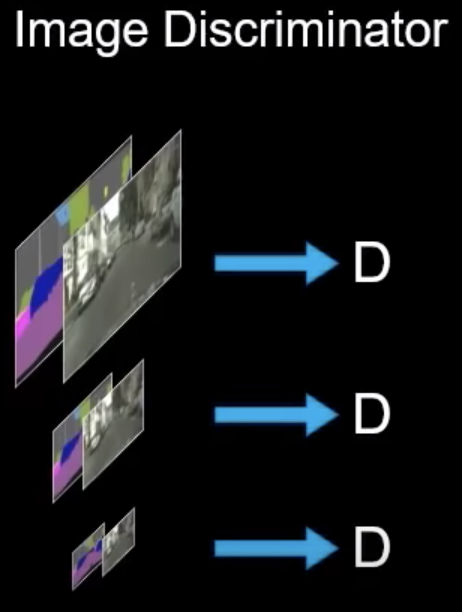
1.2 Image Discriminator
image discriminator的目的是给定相同的图片输入,让生成帧和真实帧保持一致。这和pix2pixHD的discriminator并无差别,结构也采用了Multi-scale PatchGAN。
1.3 Video Discriminator
video discriminator的目的是给定相同的光流,让连续的生成帧之间的光流信息和连续的真实帧之间的保持一致。所以image discriminator作用在图片上,video discriminator作用在光流上。
另外,vid2vid设计了temporally multi-scale video discriminator。这里“multi-scale”目的是通过采样连续帧的密度由密到疏,以便捕捉short-term和long-term的光流一致性,具体采样细节在代码get_skipped_frames中体现。每个“scale”(密度)的video discriminator都是一个Multi-scale PatchGAN。

2. DataLoader
2.1 PoseDataset
PoseDataset用来加载openpose、densepose的label和真实的img,同时在训练时做random scale和random crop。
3. Training
vid2vid训练时的loss比较多。
- 1) D_fake,D_real,G_GAN,G_GAN_Feat,G_VGG:作用在图片上的基本loss,和pix2pixHD一样
- 3) F_Flow:sequential generator生成的光流flow通过MaskedL1Loss约束,要和真实的光流flow_ref尽可能相似
- 2) G_Warp:生成的前一帧fake_B_prev通过真实的光流flow_ref warp得到的fake_B_warp_ref要和生成当前帧fake_B尽可能相似
- 4) F_Warp:真实的前一帧real_B_prev通过generator生成的光流flow warp得到的real_B_warp要和真实当前帧real_B尽可能相似
- 5) W:让generator生成的mask和全0的tensor尽可能相似??
- 6) G_f_GAN,G_f_GAN_Feat,D_f_fake,D_f_real:FaceGAN的loss,对face region的精细优化
- 7) G_T_GAN,G_T_GAN_Feat,G_T_Warp,D_T_fake,D_T_real:temporal loss,作用在采样得到的一段连续帧上的loss,T表示不同采用密度,通过n_scales_temporal设置
4. Test
利用sequential generator不断生成就可以了。